
Собственные коллекции
159C# и .NET Framework --- Оптимизация приложений .NET Framework --- Собственные коллекции
Существует множество типов коллекций, хорошо известных в информатике, но не попавших в .NET Framework. Некоторые из них получили весьма широкое распространение, и ваши приложения могли бы получить определенные выгоды от их использования. Кроме того, большинство из них может быть реализовано в достаточно короткие сроки. Не смотря на то, что мы не ставим перед собой целью заняться исследованием различных типов коллекций, тем не менее, приведем два примера коллекций, существенно отличающихся от коллекций в .NET, и предлагаем рассмотреть ситуации, когда применение собственных коллекций может оказаться полезным.
Система непересекающихся множеств
Система непересекающихся множеств (disjoint-set) - это коллекция, элементы которой хранятся в виде непересекающихся множеств. Она отличается от коллекций .NET тем, что не позволяет сохранять в ней элементы. Вместо этого образуется домен элементов, в котором каждый элемент образует единственное множество, и определяется последовательность операций по объединению в более крупные множества. Эта структура данных обеспечивает высокую эффективность двух операций:
объединение двух подмножеств с целю получить общее подмножество;
поиск, определение подмножества, которому принадлежит элемент (часто используется, чтобы определить, принадлежат ли два указанных элемента одному подмножеству).
Обычно операции с множествами выполняются на уровне элементов-представителей - с единственным представителем от каждого множества. Операции объединения и поиска принимают и возвращают представителей, а не целые множества.
Наивная реализация системы непересекающихся множеств вовлекает использование коллекции для представления каждого множества, и слияние коллекций при необходимости. Например, при использовании связанного списка для хранения каждого множества, время их слияния прямо пропорционально количеству множеств а операция поиска может занимать постоянное время, если каждый элемент имеет указатель на представителя множества.
Реализация алгоритма Галлера-Фишера (Galler-Fischer) имеет намного более высокую сложность. Множества хранятся в виде «леса» (множества деревьев); каждый узел каждого дерева хранит указатель на его родительский узел, а корнем дерева является представитель множества. Чтобы обеспечить сбалансированность получающихся деревьев, при слиянии деревьев меньшее дерево всегда присоединяется к корню большего дерева (это требует следить за глубиной дерева). Кроме того, операция поиска сжимает путь от желаемого элемента до его представителя. Ниже представлена схематическая реализация этого алгоритма:
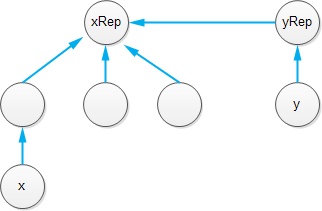
public class Set<T>
{
public Set Parent;
public int Rank;
public T Data;
public Set(T data)
{
Parent = this;
Data = data;
}
public static Set Find(Set x)
{
if (x.Parent != x)
{
x.Parent = Find(x.Parent);
}
return x.Parent;
}
public static void Union(Set x, Set y)
{
Set xRep = Find(x);
Set yRep = Find(y);
if (xRep == yRep) return; // То же самое множество
if (xRep.Rank < yRep.Rank)
xRep.Parent = yRep;
else if (xRep.Rank > yRep.Rank)
yRep.Parent = xRep;
else
{
yRep.Parent = xRep; // Объединение двух деревьев с одинаковым весом,
++xRep.Rank; // поэтому вес увеличивается
}
}
}Точное измерение производительности этой структуры данных является весьма сложной задачей. В простейшем случае верхней границей амортизированного времени операции в лесу из n элементов является O(log*n), где log*n (итерационное вычисление логарифма) - количество применений функции вычисления логарифма для получения результата меньше единицы, то есть, минимальное количество появлений «log» в неравенстве log log log ... log n < 1. Для практических значений n, например, n < 1050, это число не превышает 5 и является «почти постоянным».
Список с пропусками
Список с пропусками (skip list) - это структура данных, хранящая сортированный связанный список элементов и позволяющая выполнять поиск за время O(log n), что сравнимо со временем поиска методом дихотомии в массиве или в сбалансированном двоичном дереве.
Как известно, основной проблемой реализации поиска методом дихотомии в связанном списке является невозможность произвольного обращения к его элементам по индексу. Списки с пропусками устраняют это ограничение за счет использования иерархии все более и более разреженные связанных списков: первый связанный список связывает все узлы; второй список связывает узлы 0, 2, 4,...; третий связывает узлы 0, 4, 8,...; четвертый связывает узлы 0, 8, 16,...; и так далее.
Чтобы найти элемент в списке с пропусками, сначала выполняется обход самого разреженного списка. Когда встречается элемент, больше или равный искомому, возвращается предыдущий элемент и выполняется переход к следующему списку в иерархии. Так повторяется, пока желаемый элемент не будет найден. За счет использования в иерархии списков O(log n), гарантируется время поиска O(log n).
К сожалению, задача управления элементами списка с пропусками иногда является далеко нетривиальной задачей. Если при добавлении или удалении элемента потребуется перераспределить память для всего связанного списка, список с пропусками не сможет дать какие-либо преимущества перед обычными структурами данных, такими как сортированный список SortedList<T>, который просто хранит сортированный массив. Типичный подход к решению этой проблемы заключается в рандомизации иерархии списков (показано на рисунке ниже), что позволяет получить ожидаемое логарифмическое время на вставку, удаление и поиск элементов:
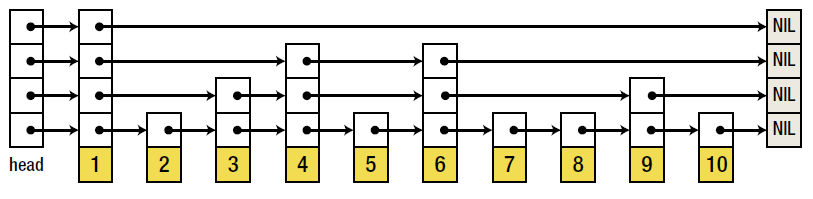
Может так же случиться, что вы окажетесь в уникальной ситуации, когда решить поставленную задачу будет возможно только с применением собственной коллекции. Мы называем их одноразовыми коллекциями (one-shot collections), потому что они являются совершенно новыми изобретениями, пригодными для решения определенной задачи. Со временем вы можете обнаружить, что какие-то из ваших одноразовых коллекций вполне можно использовать повторно. И в этом разделе мы познакомимся с одной такой коллекцией.
Представьте такую ситуацию: вы создали биржевую информационную систему, снабжающую продавцов шоколадных батончиков информацией о ценах на разные батончики. Основная таблица с данными хранится в памяти и содержит по одной строке для батончика каждого типа, содержащей текущую цену на данный батончик. В таблице ниже представлен пример этой таблицы с данными в некоторый момент времени:
| Батончик | Цена ($) |
|---|---|
| Twix | 0.93 |
| Mars | 0.88 |
| Snickers | 1.02 |
| Kisses | 0.66 |
Этой системой пользуются две категории клиентов:
Продавцы батончиков подключаются к системе через сокет TCP, и периодически запрашивают свежую информацию об определенном типе батончиков. Типичный запрос от продавца имеет вид: «Какова цена на Twix?». А типичный ответ: «$0.93». Каждую секунду в систему поступает десятки тысяч таких запросов.
Производители батончиков подключаются к системе через сокет UDP и периодически устанавливают новую цену на свои батончики. Запросы от производителей делятся на два подтипа:
«Установить цену на Mars равной $0.91». Отвечать на такой запрос не требуется. Каждую секунду в систему поступают тысячи таких запросов.
«Добавить новый батончик Snowflakes с начальной ценой $0.49». Отвечать на такой запрос не требуется. Таких запросов поступает в систему не больше нескольких десятков в день.
Известно также, что 99.9% операций чтения или обновления цены выполняется для типов батончиков, существовавших к моменту начала торгов, и только 0.1% операций выпадает на долю вновь добавленных батончиков.
Вооружившись этой информацией, вы решили спроектировать структуру данных - коллекцию - для хранения таблицы с данными в памяти. Эта структура должна поддерживать возможность использования в многопоточной среде, потому что сотни потоков выполнения могут одновременно попытаться обратиться к ней. Вам не нужно заботиться о сохранении данных в некотором постоянном хранилище - мы исследуем характеристики производительности только для случая нахождения коллекции в памяти.
Форма данных и типы запросов диктуют необходимость использовать хеш-таблицу. Синхронизация доступа к хеш-таблице является сложной задачей, которую лучше переложить на плечи ConcurrentDictionary<K,V>. Чтение из параллельного словаря можно выполнять вообще без синхронизации, а вот операции изменения цены и добавления нового типа батончиков требуют узконаправленной синхронизации. Хотя такое решение может быть вполне приемлемым, тем не менее, мы поднимем планку: нам хотелось бы обеспечить выполнение чтения и изменения цены вообще без синхронизации, в 99.9% операций с существующими типами батончиков.
Одним из возможных решений может служить безопасный-небезопасный кеш (safe-unsafe cache). Эта коллекция является множеством из двух хеш-таблиц, безопасной таблицы (safe table) и небезопасной таблицы (unsafe table). Безопасная таблица заполняется информацией о типах батончиков, существовавших к моменту начала торгов; небезопасная таблица изначально пуста. Операции с безопасной таблицей выполняются без блокировки, потому что она не изменяется; новые типы батончиков добавляются в небезопасную таблицу. Ниже представлена возможная реализация этой структуры данных с использованием Dictiornary<K,V> и ConcurrentDictionary<K,V>:
// Предполагается, что запись TValue может выполняться атомарно,
// то есть это должен быть ссылочный тип или достаточно небольшой тип значения
// (4 байта в 32-разрядных системах)
public class SafeUnsafeCache<TKey, TValue>
{
private Dictionary<TKey, TValue> safeTable;
private ConcurrentDictionary<TKey, TValue> unsafeTable;
public SafeUnsafeCache(IDictionary<TKey, TValue> initialData)
{
safeTable = new Dictionary<TKey, TValue>(initialData);
unsafeTable = new ConcurrentDictionary<TKey, TValue>();
}
public bool Get(TKey key, out TValue value)
{
return safeTable.TryGetValue(key, out value) || unsafeTable.TryGetValue(key, out value);
}
public void AddOrUpdate(TKey key, TValue value)
{
if (safeTable.ContainsKey(key))
{
safeTable[key] = value;
}
else
{
unsafeTable.AddOrUpdate(key, value, (k, v) => value);
}
}
}Следующим шагом в развитии этой структуры данных могла бы быть периодическая приостановка торговых операций и объединение безопасной и небезопасной таблиц. Это еще больше уменьшило бы потребность в синхронизации для доступа к данным.
Реализация IEnumerable<T> и других интерфейсов
Почти любая коллекция в конечном счете реализует интерфейс IEnumerable<T> и, возможно, другие интерфейсы, имеющие отношение к коллекциям. Реализация этих интерфейсов дает массу преимуществ, в том числе, начиная с версии .NET 3.5, поддержку LINQ. В конце концов, любой класс, реализующий интерфейс IEnumerable<T>, автоматически снабжается разнообразными дополнительными методами System.Linq и может использоваться в выражениях C# 3.0 LINQ, наравне со встроенными коллекциями.
К сожалению, прямолинейная реализация интерфейса IEnumerable<T> в коллекциях вынуждает вызывающую программу платить производительностью за вызовы методов интерфейса. Взгляните на следующий фрагмент, выполняющий обход коллекции List<int>:
List<int> list = // ...
IEnumerator<int> enumerator = list.GetEnumerator();
long product = 1;
while (enumerator.MoveNext()) {
product *= enumerator.Current;
}В каждой итерации в этом примере вызываются два метода интерфейса, что влечет за собой лишние накладные расходы при попытке обойти список и вычислить произведение его элементов. Встраивание методов интерфейсов не самая простая задача, и если JIT-компилятору не удастся ее решить, стоимость их вызовов получится весьма высокой.
Существует несколько решений, способных помочь избежать лишних накладных расходов при вызове методов. Когда методы интерфейсов применяются непосредственно к переменной типа значения, они вызываются напрямую. То есть, если бы переменная enumerator в примере выше имела тип значения (а не IEnumerator<T>), стоимость вызова методов интерфейса была бы намного ниже. Если бы коллекция реализовала метод GetEnumerator(), возвращающий непосредственно экземпляр типа значения, вызывающая программа смогла бы использовать его методы вместо методов интерфейса.
Для этого, например, класс List<T> явно реализует метод IEnumerable<T>.GetEnumerator(), возвращающий IEnumerator<T>, и еще один общедоступный метод GetEnumerator(), возвращающий List<T>. Enumerator - внутренний экземпляр типа значения:
public class List<T> : IEnumerable<T> // ...
{
public Enumerator GetEnumerator()
{
return new Enumerator(this);
}
IEnumerator<T> IEnumerable<T>.GetEnumerator()
{
return new Enumerator(this);
}
// ...
public struct Enumerator { ... }
}Это позволяет писать такой код:
List<int> list = // ...
List.Enumerator<int> enumerator = list.GetEnumerator();
long product = 1;
while (enumerator.MoveNext()) {
product *= enumerator.Current;
}избавляющий от вызовов методов интерфейса.
Альтернативное решение заключается в создании итератора ссылочного типа, но использующего тот же трюк с явной реализацией интерфейса - метода MoveNext() и свойства Current. Оно также позволит вызывающей программе использовать метод и свойство класса непосредственно, избежав накладных расходов на вызовы методов интерфейса.
