
Внутреннее устройство ссылочных типов C#
94C# и .NET Framework --- Оптимизация приложений .NET Framework --- Внутреннее устройство ссылочных типов C#
В этой и последующих статьях рассказывается о внутреннем устройстве типов .NET, как типы значений и ссылочные типы размещаются в памяти, какой код генерирует JIT-компилятор для вызова виртуальных методов, о хитросплетениях реализации типов значений и других тонкостях. Почему тема внутреннего устройства типов важна для оптимизации? Как эта информация может помочь в увеличении производительности приложений? Как оказывается, типы значений и ссылочные типы отличаются структурой, способом размещения в памяти, сравнения, присваивания и имеют массу других отличий, что делает правильность выбора типов весьма важным фактором, влияющим на производительность приложения.
В качестве примера мы рассмотрим простой тип Point2D, представляющий координаты точки в ограниченном двумерном пространстве. Каждая из двух координат может быть представлена значением типа short, а весь объект будет занимать четыре байта. Теперь допустим, что требуется сохранить в памяти массив с десятью миллионами точек. Какой объем памяти потребуется для этого?
Ответ на этот вопрос в значительной степени зависит от того, является ли тип Point2D ссылочным типом или типом значения. Если это ссылочный тип, массив с десятью миллионами точек будет хранить десять миллионов ссылок. В 32-разрядной системе для хранения десяти миллионов ссылок потребуется почти 40 Мбайт памяти. Сами объекты займут почти такой же объем. Фактически, как будет показано чуть ниже, каждый экземпляр Point2D занимает не менее 12 байт памяти, что в сумме для десяти миллионов точек дает 160 Мбайт памяти!
С другой стороны, если Point2D является типом значения, массив с десятью миллионами точек будет хранить десять миллионов точек и ни байтом больше, что в сумме составит 40 Мбайт, то есть в четыре раза меньше, чем для ссылочного типа, как показано на рисунке:

Такое различие в плотности размещения информации в памяти играет важную роль в выборе типов значений в определенных ситуациях.
Существует еще один недостаток ссылочных типов, в сравнении с типами значениями. Если необходимо будет выполнить обход элементов такого огромного массива точек, для компилятора и аппаратной части компьютера проще будет обеспечить доступ к смежным ячейкам памяти с объектами Point2D, чем доступ через ссылки к объектам в динамической памяти, которые необязательно будут располагаться подряд. Как будет показано позже, эффективное использование кеша процессора может поднять производительность приложения на порядок.
Совершенно очевидно, что знание и понимание особенностей размещения объектов CLR в памяти, а также и отличий между ссылочными типами и типами значений очень важно для достижения высокой производительности приложений. Итак, давайте познакомимся с основными различиями между типами значений и ссылочными типами на уровне языка, а затем погрузимся в изучение особенностей их внутреннего строения.
Семантические отличия между ссылочными типами и типами значений
К ссылочным типам в .NET относятся классы, делегаты, интерфейсы и массивы. Тип string (System.String), один из самых вездесущих типов в .NET, также является ссылочным. К типам значений в .NET относятся структуры и перечисления. Простые типы, такие как int, float, decimal тоже являются типами значений, но разработчики приложений для .NET свободно могут определять собственные типы значений с помощью ключевого слова struct.
На уровне языка, ссылочные типы обладают семантикой ссылок, в соответствии с которой главенствующее положение имеет идентичность объектов и только потом их содержимое, тогда как типы значений обладают семантикой значений, в соответствии с которой объекты не имеют идентичности, недоступны через ссылки и интерпретируются в зависимости от их содержимого. Это находит отражение в нескольких областях языков .NET, как показано в таблице ниже:
| Критерий | Ссылочные типы | Типы значений |
|---|---|---|
| Передача объекта в вызов метода | Передается только ссылка; изменения в объекте отразятся на всех остальных ссылках на него |
В параметр копируется содержимое объекта (если не используется ключевое слово ref или out); после выхода из метода изменения теряются |
| Присваивание одной переменной - другой | Копируется только ссылка; после присваивания обе переменные содержат ссылку на один и тот же объект |
Копируется содержимое; две переменные содержат идентичные копии никак не связанных между собой данных |
| Сравнение двух объектов с помощью оператора == | Сравниваются ссылки; две ссылки считаются равными, если ссылаются на один и тот же объект |
Сравнивается содержимое; два объекта считаются равными, если их содержимое идентично |
Эти семантические отличия определяют, как должен писаться программный код на любом из языков .NET. Однако это лишь вершина айсберга различий между ссылочными типами и типами значений. Рассмотрим сначала области памяти, где хранятся объекты, а также - как выделяется память для них и как она освобождается.
Хранение, размещение и удаление
Ссылочные типы хранятся исключительно в управляемой куче (динамической памяти) - области памяти, управляемой сборщиком мусора .NET. Размещение объекта в управляемой динамической памяти влечет увеличение указателя, что является весьма недорогой операцией с точки зрения производительности. В многопроцессорных системах, когда код, выполняемый на разных процессорах, обращается к одной и той же динамической памяти требуется предусмотреть некоторую синхронизацию, но процедура выделения памяти все равно остается чрезвычайно дешевой, в сравнении с процедурами в неуправляемых окружениях, таких как malloc.
Сборщик мусора освобождает память недетерминированным способом и не дает никаких гарантий, касающихся работы его внутренних механизмов. Полный процесс сборки мусора является довольно дорогостоящим, но средняя его цена в приложении, корректно использующем динамическую память, относительно невысока, если сравнивать с аналогичными механизмами в неуправляемых окружениях.
Чтобы быть до конца точными, следует заметить, что ссылочные типы могут размещаться на стеке. Массивы значений простых типов (например, массивы целых чисел) могут размещаться на стеке при использовании контекста unsafe и ключевого слова stackalloc, или встраиванием массива фиксированного размера в собственную структуру с помощью ключевого слова fixed. Однако объекты, созданные ключевыми словами stackalloc и fixed, не являются «настоящими» массивами и располагаются в памяти иначе, чем стандартные массивы.
Автономные типы значений обычно размещаются на стеке потока выполнения. Однако типы значений могут включаться в состав ссылочных типов - в этом случае они будут храниться в динамической памяти и могут упаковываться в классы, при передаче их содержимого в динамическую память. Размещение экземпляра типа значения на стеке - очень недорогая операция, которая выражается лишь в увеличении регистра указателя стека (esp - в процессорах Intel x86), и имеет дополнительное преимущество, позволяя выделять память сразу для нескольких объектов.
Фактически, для кода реализации пролога (начала) метода довольно типично единственной машинной инструкцией выделять память сразу для всех локальных переменных, объявленных в охватывающем блоке.
Освобождение памяти на стеке также выполняется весьма эффективно и требует лишь восстановления прежнего значения регистра указателя стека. Из-за особенностей компиляции методов в машинный код, компилятору часто даже не требуется запоминать общий объем, занимаемый локальными переменными метода, и он может уничтожить весь кадр стека тремя стандартными инструкциями, известными как эпилог метода.
Ниже приводится типичный пролог и эпилог управляемого метода, скомпилированного в 32-разрядный машинный код (в действительности JIT-компилятор производит несколько иной код, производя множество оптимизаций). Метод имеет четыре локальные переменные, место для которых выделяется в прологе и освобождается в эпилоге:
int Calc(int a, int b)
{
int x = a + b;
int y = a - b;
int z = b - a;
int w = 2 * b + 2 * a;
return x + y + z + w;
}; параметры передаются на стеке по адресам [esp+4] и [esp+8]
push ebp
mov ebp, esp
add esp, 16 ; выделяется место для 4 локальных переменных
mov eax, dword ptr [ebp+8]
add eax, dword ptr [ebp+12]
mov dword ptr [ebp-4], eax
; ...аналогичные действия с переменными y, z, w
mov eax, dword ptr [ebp-4]
add eax, dword ptr [ebp-8]
add eax, dword ptr [ebp-12]
add eax, dword ptr [ebp-16] ; eax содержит возвращаемое значение
mov esp, ebp ; восстанавливает кадр стека - освобождает память
; локальных переменных
pop ebp
ret 8 ; освобождает память, занимаемую двумя переменнымиКлючевое слово new в C# и других управляемых языках не означает, что место будет выделено в динамической области. Память для типа значения может быть выделена и на стеке. Например, следующая строка разместит экземпляр DateTime на стеке, инициализировав его датой, предшествующей Новому Году (System.DateTime - это тип значения):
DateTime newYear = new DateTime(2011, 12, 31);
Чем отличаются динамическая память и стек?
Вопреки общепринятому мнению, между стеком и динамической памятью в процессах .NET не так много отличий. Стек и динамическая память - не более чем области адресов в виртуальной памяти и потому адреса, зарезервированные для стека определенного потока выполнения, не обладают никакими преимуществами перед адресами, зарезервированными для динамической памяти. Доступ к динамической памяти выполняется ни быстрее, ни медленнее, чем доступ к стеку. Однако, в некоторых ситуациях использование памяти на стеке может повысить производительность в целом. Это объясняется следующими причинами:
Временные локальные значения (размещаемые близко друг от друга в смысле времени) на стеке сохраняются рядом друг с другом (в смысле адресов в памяти), а последовательное хранение на стеке обычно лучше соответствует особенностям работы кеша процессора и механизму страничной памяти системы.
Плотность размещения на стеке обычно выше, чем в динамической памяти, из-за отсутствия накладных расходов, свойственных ссылочным типам. Более высокая плотность размещения в памяти обычно означает более высокую производительность, например, потому что в кеш процессора попадет больше объектов.
Объем стека потока выполнения обычно очень невелик - в Windows по умолчанию максимальный размер стека составляет 1 Мбайт, а большинство потоков выполнения используют и того меньше - лишь несколько страниц. В современных системах стеки всех потоков в приложении могут уместиться в кеш процессора CPU, что обеспечивает чрезвычайно высокую скорость доступа к объектам, хранящимся в стеке. (Динамическая память, напротив, редко когда целиком может уместиться в кеше процессора.)
Однако, несмотря на сказанное выше, не следует стремиться все и вся размещать на стеке! Объем стека потока выполнения в Windows ограничен и его легко исчерпать в случае слишком глубокой рекурсии или попытавшись разместить на стеке слишком много объектов, вызвав тем самым исключение StackOverflowException.
Разобравшись с различиями между типами значений и ссылочными типами, лежащими на поверхности, можно перейти к исследованию их внутренней реализации, также объясняющей огромные отличия в плотности размещения в памяти, уже несколько раз упоминавшейся выше. Но, прежде чем мы приступим, необходимо предупредить вас, что особенности, описываемые ниже, являются особенностями внутренней реализации CLR, которые могут измениться в любой момент без каких-либо уведомлений. Мы сделали все возможное, чтобы гарантировать полное соответствие информации версии .NET 4.5, но мы не можем обещать, что она останется верной в будущих версиях.
Устройство ссылочных типов
Сначала мы разберемся со ссылочными типами, имеющими весьма сложную организацию в памяти, что оказывает существенное влияние на производительность. В дальнейшем обсуждении мы будем рассматривать пример ссылочного типа Employee, имеющего несколько полей (экземпляра и статических), а также несколько методов:
public class CompanyPolicy
{
public bool CanTakeVacation(Employee e) { return true; }
}
public class Employee
{
private int _id;
private string _name;
private static CompanyPolicy _policy;
public virtual void Work()
{
Console.WriteLine("Zzzz...");
}
public void TakeVacation(int days)
{
Console.WriteLine("Zzzz...");
}
public static void SetCompanyPolicy(CompanyPolicy newPolicy)
{
_policy = newPolicy;
}
}Теперь посмотрим, как располагается экземпляр ссылочного типа Employee в динамической памяти. На рисунке ниже представлена схема размещения объекта в 32-разрядном процессе .NET:

Порядок следования полей _id и _name внутри объекта не обязательно будет таким, как на рисунке (хотя есть возможность управлять им с помощью атрибута StructLayout).
В начале области памяти, занимаемой объектом, находятся четыре байта слова заголовка объекта (индекса блока синхронизации), за которыми следуют четыре байта указателя на таблицу методов (или указатель на тип объекта). Эти поля недоступны непосредственно ни в одном из языков .NET - они используются JIT-компилятором и средой выполнения CLR. Ссылка на объект (которая фактически является всего лишь адресом в памяти) указывает на указатель таблицы методов, поэтому слово заголовка объекта находится с отрицательным смещением относительно адреса объекта.
В 32-разрядных системах, объекты размещаются в динамической памяти по адресам, кратным 4. Это означает, что объект с единственным полем, размером 1 байт, все равно будет занимать 12 байт в памяти, из-за выравнивания (фактически, даже экземпляр класса, не имеющего ни одного поля, будет занимать 12 байт).
В 64-разрядных системах имеются свои отличия. Во-первых, указатель на таблицу методов занимает 8 байт, и слово заголовка объекта так же занимает 8 байт. Во-вторых, объекты размещаются в динамической памяти по адресам, кратным 8. Это означает, что объект с единственным полем, размером 1 байт, будет занимать 24 байта в памяти. Эти цифры приведены, только чтобы показать, насколько увеличиваются накладные расходы при массовом размещении маленьких объектов ссылочных типов.
Таблица методов
Поле указателя на таблицу методов ссылается на внутреннюю структуру CLR под названием таблица методов (method table), которая в свою очередь ссылается на другую внутреннюю структуру под названием EEClass (где ЕЕ, это аббревиатура от Execution Engine - механизм выполнения). Вместе, таблица методов и EEClass, содержат информацию, необходимую для выбора виртуального метода, метода интерфейса, статической переменной, определения типа объекта во время выполнения, доступа к методам базового класса и многих других целей.
Таблица методов содержит часто используемую информацию, требуемую для выполнения операций такими механизмами, как механизм выбора виртуального метода, а структура EEClass содержит информацию, используемую реже, например механизмом рефлексии. Ознакомиться с содержимым обеих структур данных можно с помощью команд !DumpMT И !DumpClass библиотеки SOS, в исходных текстах Rotor реализации .NET - Shared Source Common Language Infrastructure - SSCLI, но имейте в виду, что рассматриваемые здесь детали внутренней реализации могут существенно отличаться в разных версиях CLR.
SOS (Sort of Strike) - это DLL-библиотека, расширение отладчика, упрощающая отладку управляемых приложений с применением отладчиков Windows. Чаще всего используется совместно с WinDbg, но может также загружаться в Visual Studio с помощью Immediate Window (Окно команд). Команды, поддерживаемые расширением, позволяют проникнуть вглубь CLR, и именно поэтому мы часто будем использовать их. За дополнительной информацией о библиотеке SOS обращайтесь к встроенной документации (команда !help, доступная после загрузки расширения) и к документации на сайте MSDN.
Размещение статических полей определяется структурой EEClass. Поля простых типов (например, целые числа) сохраняются в динамически выделенных областях, в памяти загрузчика, а экземпляры пользовательских ссылочных типов и типов значений сохраняются в виде косвенных ссылок на области в динамической памяти (через массив объектов AppDomain).
Чтобы получить доступ к статическому полю, необязательно обращаться к таблице методов или к структуре EEClass - JIT-компилятор «жестко зашивает» адреса статических полей в генерируемый им машинный код. Массив ссылок на статические поля фиксируется так, что его адрес не может быть изменен сборщиком мусора, кроме того, статические поля простых типов размещаются внутри таблицы методов, которая не затрагивается сборщиком мусора. Это гарантирует, что для доступа к таким полям можно без опаски использовать жестко зашитые адреса:
public static void SetCompanyPolicy(CompanyPolicy newPolicy)
{
_policy = newPolicy;
}
mov ecx, dword ptr [ebp+8] ; копировать параметр в ECX
mov dword ptr [0x3543320], ecx ; копировать ECX в статическое поле в глобальном массивеНаиболее очевидной информацией, хранимой в таблице методов, является массив адресов, по одному для каждого метода, включая виртуальные методы, унаследованные от базового типа. Например, на рисунке ниже показана возможная схема размещения в памяти экземпляра класса Employee, представленного выше, при этом предполагается, что он наследует только класс System.Object:

Для исследования таблиц методов можно использовать команду !DumpMT библиотеки SOS, применив ее к указателю на таблицу методов (его можно получить из первого поля имеющегося объекта, на который указывает ссылка на объект, или с помощью команды !Name2EE). Ключ -md выведет таблицу дескрипторов методов, содержащую адреса и дескрипторы методов. (Колонка JIT может иметь три значения: PreJIT, если метод скомпилирован с помощью NGEN; JIT, если метод скомпилирован JIT-компилятором во время выполнения; или NONE, если метод еще не был скомпилирован.)

В отличие от таблиц указателей на виртуальные функции в языке C++, таблицы методов в CLR содержат адреса для всех методов, включая и невиртуальные. Порядок следования методов в таблице не определен. В настоящее время они располагаются в следующем порядке: унаследованные виртуальные методы (включая переопределяющие их - обсуждается ниже), новые виртуальные методы, невиртуальные методы экземпляра и статические методы.
Адреса в таблице методов генерируются «на лету» - JIT-компилятор компилирует методы при первом обращении к ним, если они не были скомпилированы инструментом NGEN. Однако, пользователям таблицы методов нет нужды знать такие тонкости, благодаря распространенной особенности компилятора. В момент создания таблицы методов, она заполняется специальными «заглушками», содержащими единственную инструкцию call, вызывающую процедуру компиляции соответствующего метода. После компиляции заглушка затирается инструкцией jmp, передающей управление вновь скомпилированному методу. Вся структура данных, хранящая заглушку и некоторую дополнительную информацию о методе, называется дескриптором метода (method descriptor, MD) и доступна для исследования с помощью команды !DumpMD библиотеки SOS.
До того, как метод будет скомпилирован JIT-компилятором, его дескриптор содержит следующую информацию:
... IsJitted: no ...
Ниже приводится пример заглушки, ответственной за обновление дескриптора метода:

После компиляции метода, его дескриптор принимает следующий вид:
... IsJitted: yes CodeAddr: 00490140 ...
В действительности таблица методов содержит больше информации, чем было показано выше. Описание некоторых дополнительных полей, играющих важную роль в выборе метода при вызове, обсуждается далее, - именно по этой причине нам необходимо внимательнее рассмотреть структуру таблицы методов экземпляра класса Employee. Допустим, что класс Employee дополнительно реализует три интерфейса: IComparable, IDisposable И ICloneable. На рисунке ниже изображено несколько дополнительных деталей в таблице методов:
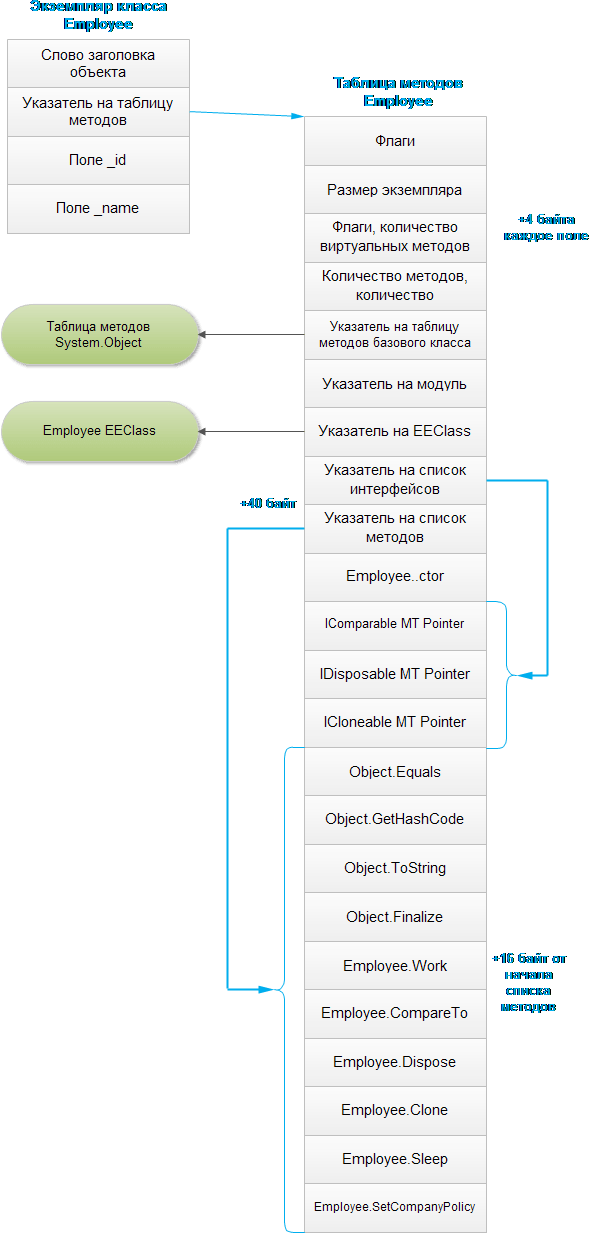
Во-первых, заголовок таблицы методов содержит несколько интересных флагов, позволяющих динамически исследовать ее структуру, в том числе: количество виртуальных методов и количество реализованных интерфейсов. Во-вторых, таблица методов содержит указатель на таблицу методов базового класса, указатель на модуль и указатель на структуру EEClass (которая содержит обратную ссылку на таблицу методов). В-третьих, фактическим методам предшествует список таблиц методов интерфейсов, реализуемых классом. Именно поэтому указатель на список методов в таблице методов находится со смещением 40 байт от начала таблицы методов.
Дополнительная операция разыменования указателя, необходимая для перехода к таблице адресов методов, позволяет хранить эту таблицу отдельно от таблицы методов объекта, в другой области памяти. Например, если попробовать исследовать таблицу методов класса System.Object, можно обнаружить, что адреса методов хранятся в другом месте. Кроме того, классы с большим количеством виртуальных методов будут иметь несколько указателей на таблицы, обеспечивая повторное использование таблиц методов в классах-наследниках.
Вызов методов экземпляров ссылочных типов
Очевидно, что таблица методов может использоваться для вызова методов произвольных экземпляров. Допустим, что на стеке, по адресу EBP-64, хранится адрес объекта Employee, схема таблицы методов которого была представлена на рисунке. Тогда мы можем вызвать виртуальный метод Work, используя следующую последовательность инструкций:
mov ecx, dword ptr [ebp-64]
mov eax, dword ptr [ecx] ; указатель на таблицу методов
mov eax, dword ptr [eax+40] ; указатель на фактический список методов в таблице
call dword ptr [eax+16] ; Work - пятое поле (четвертое, если считать с нуля)Первая инструкция копирует ссылку со стека в регистр ecx, вторая - разыменовывает регистр ecx, чтобы получить указатель на таблицу методов объекта, третья - извлекает внутренний указатель на список методов в таблице методов (который находится с постоянным смещением 40 байт), и четвертая - разыменовывает элемент списка со смещением 16, чтобы получить адрес метода Work и вызвать его. Чтобы понять, зачем необходимо использовать таблицу методов для диспетчеризации виртуальных методов, рассмотрим, как происходит привязка во время выполнения - то есть, как с помощью виртуальных методов реализуется полиморфизм.
Допустим, что имеется еще один класс Manager, наследующий класс Employee и переопределяющий его виртуальный метод Work, а также реализующий еще один интерфейс:
public class Manager : Employee, ISerializable
{
private List<Employee> _reports;
public override void Work()
{
base.Work();
}
// Реализация интерфейса ISerializable
public void GetObjectData(SerializationInfo info, StreamingContext context)
{
throw new NotImplementedException();
}
}
Компилятору может потребоваться вызвать метод Manager.Work() через ссылку на объект типа Employee, как показано в следующем фрагменте:
Employee employee = new Manager();
employee.Work();В данном конкретном случае компилятор мог бы решить - используя приемы статического анализа - что должен вызываться метод Manager.Work (чего не происходит в текущих реализациях C# и CLR). В общем случае, однако, когда имеется статическая ссылка типа Employee, компилятор должен отложить привязку методов во время выполнения. В действительности, единственный способ привязать правильный метод - определить фактический тип объекта во время выполнения и вызвать виртуальный метод, основываясь на этой информации. Именно это и позволяет сделать таблица методов.
Как изображено на рисунке ниже, поле, соответствующее методу Work, в таблице методов класса Manager содержит иной адрес, а последовательность выбора метода остается прежней. Обратите внимание, что смещение переопределенного поля с адресом метода отличается, потому что класс Manager реализует дополнительный интерфейс; однако поле «Указатель на список методов» имеет то же смещение и нивелирует это отличие:

mov ecx, dword ptr [ebp-64]
mov eax, dword ptr [ecx]
mov eax, dword ptr [ecx+40] ; нивелирует различия в смещении метода Work
call dword ptr [eax+16] ; абсолютное смещение от начала таблицы методов
Поддержка схемы размещения объектов, не гарантирующей, что смещение местоположения переопределенных методов от начала таблицы методов будет одинаковым в родительском и дочернем классах, впервые появилась CLR 4.0. В предыдущих версиях CLR список интерфейсов, реализуемых типом, хранился в конце таблицы методов, после списка адресов; это означало, что смещение адреса метода Object.Equals (и всех других адресов реализаций методов) было постоянным во всех производных классах. А это, в свою очередь, означало, что последовательность вызова виртуального метода состояла всего из трех инструкций вместо четырех (третья инструкция в последовательности выше была не нужна). В старых статьях и книгах можно увидеть упоминание последовательности вызова из трех инструкций, что служит яркой демонстрацией, как может изменяться внутренняя реализация CLR.
Вызов невиртуальных методов
Аналогичную последовательность инструкций можно также использовать для вызова невиртуальных методов. Но при обращении к невиртуальным методам нет необходимости использовать таблицу методов: адрес метода (или, по крайней мере, заглушки для JIT-компилятора) известен, когда JIT-компилятору потребуется скомпилировать вызов метода. Например, если на стеке, по адресу EBP-64, хранится адрес объекта Employee, как и в предыдущих примерах, тогда последовательность инструкций вызова метода TakeVacation() с параметром 5 будет следующей:
mov edx, 5 ; параметр передается в регистре - в соответствии с соглашениями
mov ecx, dword ptr [ebp-64] ; все еще необходимо, потому что ECX содержит 'this'
call dword ptr [0x004a1260]Перед вызовом все еще необходимо загрузить адрес объекта в регистр ecx - все методы экземпляров ожидают получить этот неявный параметр в регистре ecx. Однако, больше не нужно разыменовать указатель на таблицу методов и получать адрес метода из нее. Но JIT-компилятору все еще требуется возможность изменить адрес вызова после вызова; поэтому выполняется косвенный вызов по адресу, хранящемуся в ячейке памяти (0x004a1260 в этом примере), которая первоначально хранит адрес заглушки JIT-компилятора и обновляется им сразу после компиляции метода.
К сожалению, последовательность инструкций, представленная выше, страдает одним существенным недостатком. Она допускает возможность, вызова метода с пустой ссылкой на объект, что может остаться незамеченным, пока метод экземпляра не попытается обратиться к полю экземпляра или вызвать виртуальный метод, что может вызвать ошибку нарушения прав доступа. В действительности это является характерным поведением процедуры вызова методов экземпляров в языке С++ - следующий код выполнится без ошибок в большинстве окружений С++.
Причина нашего интереса к таким тонким отличиям вызовов виртуальных и невиртуальных методов вовсе не в дополнительной инструкции обращения к памяти и не в наличии или отсутствии других инструкций. Главная причина состоит в том, что виртуальные методы препятствуют оптимизации, выражающейся во встраивании методов, чрезвычайно важной для современных высокопроизводительных приложений. Встраивание - это очень простой трюк компилятора, когда вызов короткого или простого метода замещается его телом. Например, в следующем фрагменте вполне разумно было бы заменить вызов метода Add единственной операцией, выполняемой в нем:
int Add(int a, int b)
{
return a + b;
}
// ...
int С = Add(10, 12);
// предположим, что переменная c будет использоваться далее в кодеНеоптимизированная последовательность будет состоять почти из 10 инструкций: три - для подготовки параметров и вызова метода, две - для подготовки кадра стека метода, одна - для сложения операндов, две - для освобождения кадра стека метода и одна - для выхода из метода. Оптимизированная последовательность вызова будет состоять из единственной инструкции - догадались какой? Вполне логично предположить, что это будет инструкция add, но в действительности здесь может быть использована другая оптимизация, называемая сверткой констант, которая производит вычисление результата на этапе компиляции и присваивает переменной С значение 22.
Разница в производительности встроенных и невстроенных вызовов методов может быть просто громадной, особенно когда методы просты, как в примере выше. Свойства, например, являются отличными кандидатами на встраивание, а автоматические свойства, генерируемые компилятором - тем более, потому что не содержат никакой логики, кроме прямого обращения к полю. Однако, виртуальные методы препятствуют встраиванию, потому что данная оптимизация может применяться, только когда на этапе компиляции (в случае с JIT-компилятором - на этапе JIT-компиляции) известно, какой именно метод вызывается.
Когда адрес вызываемого метода определяется на этапе выполнения исходя из информации о типе, встроенной в объект, нет никакой возможности корректно выполнить встраивание виртуального метода. Если бы все методы были виртуальными по умолчанию, свойства так же были бы виртуальными, а накопленная потеря производительности, обусловленная косвенными вызовами методов там, где иначе можно было бы применить встраивание, была бы просто ошеломляющей.
Кого-то может заинтересовать эффект влияния ключевого слова sealed на процедуру вызова метода, особенно теперь, когда мы познакомились с оптимизацией, выполняющей встраивание. Например, если в классе Manager метод Work объявить как sealed, вызов его по ссылке на объект, имеющей статический тип Manager, можно выполнить, как если бы он был невиртуальным методом экземпляра:
public class Manager : Employee
{
public override sealed void Work()
{
base.Work();
}
}
// ...
Manager manager = ...; // может быть экземпляром Manager или производного типа
manager.Work(); // здесь возможен прямой вызов!Тем не менее, на момент написания этих строк ключевое слово sealed не оказывало влияния на вызов методов во всех версиях CLR, протестированных нами, хотя знание, что класс или метод является конечным (sealed) позволяет использовать более эффективную последовательность инструкций вызова невиртуальных методов.
Вызов статических методов и методов интерфейсов
Для полноты картины необходимо обсудить еще две разновидности методов: статические методы и методы интерфейсов. Вызов статических методов выполняется очень просто: в этом случае нет необходимости загружать ссылку на объект и достаточно просто вызвать метод (или заглушку JIT-компилятора). Поскольку вызов выполняется без использования таблицы методов, JIT-компилятор применяет тот же трюк, что и в случае невиртуальных методов экземпляра: вызов выполняется косвенно, через специальную ячейку в памяти, которая обновляется после JIT-компиляции метода.
Однако методы интерфейсов - совершенно иное дело. Может показаться, что вызов метода интерфейса ничем не отличается от вызова виртуального метода экземпляра. Однако это не так. Интерфейсы обеспечивают разновидность полиморфизма, напоминающего классические виртуальные методы. К сожалению, нет никакой гарантии, что реализации методов какого-то определенного интерфейса окажутся в тех же позициях в таблице методов во всех классах, реализующих этот интерфейс. Взгляните на следующий фрагмент, где представлены два класса, реализующих интерфейс IComparable:
class Manager : Employee, IComparable
{
public override void Work()
{
// ...
}
public void TakeVocation(int days)
{
// ...
}
public static void SetCompanyPolicy(/*...*/)
{
// ...
}
public int CompareTo(object obj)
{
// ...
}
}
class BigNumber : IComparable
{
public long Part1, Part2;
public int CompareTo(object other)
{
// ...
}
}Очевидно, что таблицы методов в этих классах будут иметь разную структуру, и номер слота, ссылающегося на метод CompareTo в них, будет отличаться. Сложность иерархии объектов и наличие реализаций множества интерфейсов делают очевидной необходимость дополнительной идентификации местоположения методов интерфейсов в таблице методов.
В предыдущих версиях CLR эта информация хранилась в глобальной таблице (на уровне AppDomain), индексируемой числовым идентификатором интерфейса, генерируемым при первой загрузке интерфейса. В таблице методов имеется специальное поле (со смещением 12), указывающее на соответствующее место в глобальной таблице интерфейсов, а поля в глобальной таблице интерфейсов ссылаются обратно на таблицу методов, точнее на подтаблицу внутри нее, где хранятся указатели на методы. Такое решение обеспечивает возможность вызова методов в несколько этапов, как показано ниже:
mov ecx, dword ptr [ebp-64] ; ссылка на объект
mov eax, dword ptr [ecx] ; указатель на таблицу методов
mov eax, dword ptr [eax+12] ; указатель на карту интерфейсов
mov eax, dword ptr [eax+48] ; смещение данного интерфейса в карте,
; определяемое на этапе компиляции
call dword ptr [eax] ; первый метод по адресу EAX, второй - по адресу EAX+4, и т.д.Выглядит очень сложно и весьма недешево! Для получения адреса реализации метода интерфейса и его вызова требуется четырежды обратиться к памяти. Для некоторых интерфейсов это может оказаться слишком дорогим удовольствием. Именно поэтому вы никогда не увидите такую последовательность инструкций, даже после отключения всех оптимизаций. JIT-компилятор использует несколько трюков, чтобы обеспечить встраивание методов интерфейсов, по крайней мере, в наиболее типичных случаях.
Анализ горячего пути (hot-path analysis) - когда JIT-компилятор обнаруживает частое использование одной и той же реализации интерфейса, он заменять конкретную процедуру вызова оптимизированным кодом и может даже встраивать часто используемые реализации интерфейсов:
mov ecx, dword ptr [ebp-64]
cmp dword ptr [ecx], 00385670 ; ожидается указатель на таблицу методов
jne 00a188c0 ; "холодный путь", показан ниже в псевдокоде
jmp 00a19548 ; "горячий путь", здесь может быть встроено тело метода// "холодный путь":
if (--wrongGuessesRemaining < 0) // начальное значение 100
{
// заменить процедуру вызова в коде, как обсуждается ниже
}
else {
// стандартный вызов метода интерфейса
}Частотный анализ (frequency analysis) - когда JIT-компилятор обнаруживает, что выбор горячего пути не соответствует конкретному вызову (по серии нескольких вызовов), он замещает ожидаемый горячий путь новым горячим путем и продолжает выбирать между ними всякий раз, когда предположения оказываются неверными:
start: if (obj->MTP == expectedMTP) {
// прямой переход к ожидаемой реализации
} else {
expectedMTP = obj->MTP;
goto start;
}Вызов метода интерфейса - это давно и активно обсуждаемая тема; в будущих версиях CLR могут появиться другие оптимизации, не обсуждавшиеся здесь.
Блоки синхронизации и ключевое слово lock
Второе поле, встраиваемое во все экземпляры ссылочных типов - это слово заголовка объекта (или индекс блока синхронизации). В отличие от указателя на таблицу методов, это поле используется для самых разных целей, таких как синхронизация, хранение служебной информации сборщика мусора, финализация и хранение хеш-кода. Некоторые биты этого поля определяют, какая информация хранится в нем в каждый конкретный момент.
Самым сложным является использование слова заголовка объекта механизмом мониторинга CLR для синхронизации, взаимодействие с которым в языке C# осуществляется с помощью ключевого слова lock. Суть заключается в следующем: несколько потоков выполнения могут попытаться одновременно выполнить фрагмент кода, защищенного инструкцией lock, но только одному из них будет позволено это:
class Counter
{
private int _i;
private object _syncObject = new object();
public int Increment()
{
lock (_syncObject)
{
return ++_i; // только один поток сможет выполнить эту инструкцию
}
}
}Однако ключевое слово lock - это лишь синтаксический сахар, скрывающий в себе следующую конструкцию, использующую методы Monitor.Enter И Monitor.Exit:
class Counter
{
private int _i;
private object _syncObject = new object();
public int Increment()
{
bool acquired = false;
try
{
Monitor.Enter(_syncObject, ref acquired);
return ++_i;
}
finally
{
if (acquired)
Monitor.Exit(_syncObject);
}
}
}Чтобы обеспечить исключительную блокировку, механизм синхронизации можно связать с любым объектом. Поскольку инициализация механизма синхронизации для каждого объекта в приложении - слишком дорогое удовольствие, она выполняется только по требованию, когда объект впервые используется для синхронизации. Когда это потребуется, среда выполнения CLR создаст структуру, которая называется блоком синхронизации (sync block), в глобальном массиве, называемом таблицей блоков синхронизации (sync block table).
Блок синхронизации содержит обратную ссылку на объект, владеющий блоком (это - «слабая» ссылка, не мешающая утилизации объекта сборщиком мусора), и, кроме всего прочего, ссылку на механизм синхронизации, называемый монитором (monitor), реализация которого основана на событиях Win32. Числовой индекс созданного блока синхронизации будет сохранен в слове заголовка объекта. При последующих попытках использовать объект для нужд синхронизации, из него будет извлечен индекс существующего блока синхронизации и задействован соответствующий объект монитора.

На рисунке видно, что поле индекса блока синхронизации хранит только индекс в таблице блоков синхронизации, что дает среде выполнения CLR возможность свободно изменять размеры и перемещать таблицу синхронизации в памяти. Когда блок синхронизации не используется достаточно продолжительное время, сборщик мусора утилизирует его и разрывает связь между им и его объектом-владельцем, записывая в поле индекса блока синхронизации недопустимое значение. После утилизации блок синхронизации может быть связан с другим объектом, что позволяет сэкономить системные ресурсы, необходимые для инициализации механизма синхронизации.
С помощью команды !SyncBlk библиотеки SOS можно исследовать конкурирующие блоки синхронизации, то есть блоки, которыми владеют потоки выполнения, ожидающие, пока блокировка будет освобождена другим потоком (таких ожидающих потоков выполнения может быть несколько). В версии CLR 2.0 была добавлена оптимизация, откладывающая создание блока синхронизации до момента, когда он потребуется для нужд синхронизации. Пока блок синхронизации отсутствует, среда выполнения CLR может управлять состоянием синхронизации с помощью тонких блокировок (thin lock). Некоторые примеры приводятся ниже.
Для начала рассмотрим слово заголовка объекта, которые еще не использовался для синхронизации, но хеш-код в котором уже доступен (хеш-коды ссылочных типов мы обсудим позже). В следующем примере регистр EAX указывает на объект Employee, имеющий хеш-код 46104728:

Здесь отсутствует индекс блока синхронизации - имеется только хеш код и два бита установлены в 1, один из них, видимо, указывает, что слово заголовка объекта сейчас хранит хеш-код. Далее был выполнен вызов Monitor.Enter для объекта в одном из потоков выполнения, чтобы заблокировать его:

Объект был связан с блоком синхронизации 1, что доказывает вывод команды !SyncBlk (дополнительную информацию о колонках в выводе команды можно найти в документации к библиотеке SOS). Когда другой поток выполнения попытается выполнить инструкцию lock с тем же объектом, он попадет в стандартный цикл ожидания (допускающий возможность обработки сообщений, если этот поток обслуживает графический интерфейс пользователя). Ниже приводится дамп дна стека потока выполнения, ожидающего на мониторе:

Для синхронизации используется объект 25c, являющийся дескриптором (handle) события:

И, наконец, если заглянуть в память блока синхронизации, связанного с этим объектом, можно будет без труда опознать хеш-код и дескриптор механизма синхронизации:

Обратите также внимание, что в предыдущем примере мы принудительно инициировали создание блока синхронизации, вызвав GetHashcode() перед попыткой получить блокировку. В версии CLR 2.0 была добавлена еще одна оптимизация, позволяющая экономить время и память, - блок синхронизации не создается, если прежде объект не был связан с блоком синхронизации. Вместо этого CLR использует механизм, получивший название тонкая блокировка (thin lock). Когда объект блокируется первый раз и конкуренция за его обладание отсутствует (то есть, никакой другой поток выполнения не попытался заблокировать объект), CLR сохраняет в слове заголовка объекта идентификатор управляемого потока выполнения, владеющего объектом в настоящий момент.
Например, ниже приводится пример слова заголовка объекта, заблокированного главным потоком приложения до того, как какой-либо другой поток попытался сделать то же самое:

Здесь управляемый поток выполнения с идентификатором 1 - это главный поток приложения, в чем можно убедиться, выполнив команду !Threads:

Тонкая блокировка также обнаруживается командой !DumpObj, которая указывает также поток выполнения, захвативший блокировку. Аналогично, с помощью команды !DumpHeap -thinlock можно вывести все тонкие блокировки, присутствующие в настоящее время в управляемой динамической памяти:

Когда другой поток выполнения попытается заблокировать объект, он будет приостановлен на короткое время, в ожидании снятия тонкой блокировки (то есть, когда информация о владельце исчезнет из слова заголовка объекта). Если в течение некоторого ограниченного времени блокировка не будет освобождена, она будет преобразована в блок синхронизации, индекс блока синхронизации будет сохранен в слове заголовка объекта, и с этого момента блокировкой потока выполнения будет управлять обычный механизм синхронизации Win32.
